

ペタスケールコンピューティングを支える基盤技術



生命体基盤ソフトウェア開発・高度化チーム
小野 謙二(左)
伊東 聰(中)
渡邉 大介(右)
生命体基盤ソフトウェア開発・高度化チームでは、高性能なアプリケーションを開発するための要素技術やソフトウェア開発の枠組みなどの研究開発を行っています。これらの技術は、次世代生命体統合シミュレーションソフトウェアの研究開発プロジェクトで開発されるアプリケーションの高性能化やソフトウェア開発の効率化に貢献しています。また、大規模なシミュレーションの計算結果を効率的・効果的に可視化し、結果に含まれる情報を分かり易く表現する可視化システムを開発中です
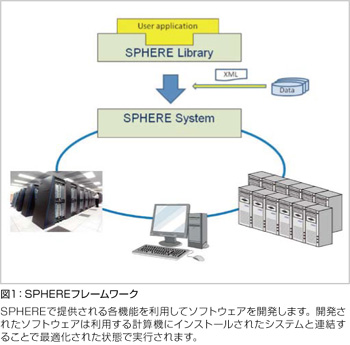
現在のスーパーコンピュータはすべて複数のCPU/コアで構成される並列計算機です。並列計算機を用いるにはソフトウェアの並列化(インプットデータの分割やデータ通信)と最適化が必要です。並列化は純粋にプログラミングの問題であり、ソフトウェアの開発者にとって大きな負担となっています。最適化されていないソフトウェアは並列計算機の性能を数%程度しか引き出せないため、並列最適化は並列計算機の利用に必須な処理です。しかし、最適化は計算機ごとに処理内容が異なり移植性を著しく低減させてしまいます。大規模なシミュレーションシステムの開発で生じるこのような問題点を緩和するために、アプリケーション・ミドルウェアSPHEREを開発しています(図1)。SPHEREは、ソフトウェアの開発と運用の両面をサポートし、データの入出力や内積などの代数処理、境界条件処理などの機能が提供されており、ソフトウェアの効率的な開発に役立ちます。各機能はすべて並列化されており、開発したソフトウェアはそのまま並列計算機で実行が可能になります。各機能は各種計算機用に最適化されているので、高い実行性能も期待できます。今後、自動チューニング技術を導入し、最適な解法やパラメータを実行時に自動選択し、高い実効性能を狙います。運用に関しては、XMLファイルを用いたパラメータ記述や実行管理をしており、複数のソフトウェアに対して統一フォーマット(解析条件設定、ファイル名指定など)が適用され、運用に関する負荷が大幅に軽減されます。また、各種ユーティリティー(XMLファイル作成補助、境界条件およびデータ分割、可視化)も充実しており、解析全体を通しての運用効率が高められます。このようなSPHEREの機能は、産業利用向けアプリケーションの開発効率化を意図しており、数千並列程度の高性能化を目標としています。
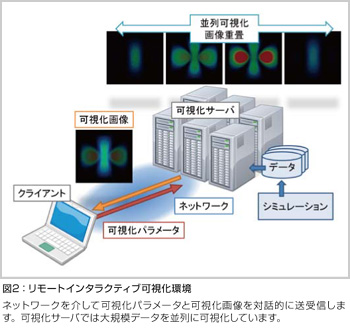
次世代スーパーコンピュータでは極めて大規模な数値シミュレーションが行われ、その計算結果は巨大なファイル群として出力されます。それらのデータを効率的に理解・解析するために、私たちは数百TBにおよぶと予想される大規模データを対象として、機能的なデータマネージメントと可視化システムの研究開発を行っています。この可視化システムでは、大規模なデータに対するインタラクティブな可視化環境を提供することが目標です (図2)。ユーザが観察したい領域や可視化パラメータを対話的に操作し、データの視覚的な調査をリアルタイムに繰り返すことにより、現象理解を支援します。可視化システムはサーバ/クライアント型で設計されており、並列分散処理を行います。可視化画像の描画に、各ノードでGPUが使用できる場合はより高速・高品質な可視化を行います。また、大規模データのロードや転送のコストを削減するために、単純な領域選択やダウンサンプリングに加え、データの必要な部分だけを適宜ロードするOut-of-Core技術や、データの高速・高圧縮技術の開発にも取り組んでいます。さらに、汎用的な利用形態を考慮し、ユーザPC単体でのローカル可視化や、予め定義したシナリオに基づいて可視化するバッチ処理といった機能を提供します。開発する可視化システムにより、大規模なシミュレーションの結果から新しい物理化学現象や有用な情報を引き出し、科学的な発見へ貢献します。
BioSupercomputing Newsletter Vol.1
- SPECIAL INTERVIEW
- 生命現象の本質に迫る革新的なアプローチ バイオスーパーコンピューティングによる挑戦が始まる
次世代計算科学研究開発プログラム 副プログラムディレクター 姫野 龍太郎
- LEADER’S TALK
- 生命活動の基礎となる生体高分子が担う機能をシミュレーションによってとらえる
分子スケール研究開発チーム チームリーダー 木寺 詔紀 - 三次元的に人体の全身モデルを構築して生体内で起こる現象を理解し、医療に役立てる
臓器全身スケール研究開発チーム チームリーダー 高木 周 - 第4の方法論「データ解析融合」によってバイオロジーを予測可能な科学へと導く
データ解析融合研究開発チーム チームリーダー 宮野
- 研究報告
- レプリカ交換分子動力学法によるアミロイド前駆体蛋白質の膜貫通部位の二量体構造予測
分子スケール研究開発チーム 宮下 尚之 /理化学研究所 基幹研究所 杉田 有治 - 重粒子線治療シミュレーション
臓器全身スケール研究開発チーム 石川 顕一 - ゲノムワイド関連解析と遺伝的、非遺伝的要因による治療予後予測の展望
理化学研究所ゲノム医科学研究センター 鎌谷 直之 - ペタスケールコンピューティングを支える基盤技術
生命体基盤ソフトウェア開発・高度化チーム 小野 謙二 / 伊東 聰 / 渡邉 大介
- ワークショップ報告
- VPHとのジョイントワークショップを開催