

データ解析融合研究開発チーム
第4の方法論「データ解析融合」によって
バイオロジーを予測可能な科学へと導く

データ解析融合研究開発チーム
チームリーダー
宮野 悟
こんなことを言うとお叱りを受けるかもしれませんが、実はバイオロジー(生物学)は、サイエンス分野で唯一サイエンティフィックな言葉を持っていない科学なのです。ほとんど原理と言えるものが見つかっておらず、基本的にファクト、つまり数学で言えば定理に当たるようなものを常に書き続けているばかりなのです。例えば、「この遺伝子はこの遺伝子群を制御していて、その結果、このフェノタイプ(表現型)の原因になっている」ということを分子生物学的に証明して、ファクトを書き続けているわけです。それはそれなりに魅力的なことではあるのですが、これでは単に「あれが見つかった」、「これが見つかった」と言い続けているだけのことで、それを1000年続けても、ライフサイエンスは予測可能な科学にはなりません。
2003年に米国国立衛生研究所(NIH)が、ヒトゲノム解読後のバイオメディカルリサーチのロードマップを出しました。そのなかに「All ofthese techniques generate large amounts of data, and biologyis changing fast into a science of information management.」という一文があります。当時、このメッセージは生物学や医学関係者にとって大きな驚きでした。しかし、今となっては誰もがそうなりつつあることを強く実感しています。つまり、データを出していくことはもちろん重要なことですが、バイオロジーはその大量のデータをどのように解析し、解釈していくかというサイエンスになろうとしているということです。そうして、膨大な数のファクトをうまく使えるものにしていくとともに、バイオロジーを予測可能な科学にしていくことが求められています。ライフサイエンスにおける計算科学の重要性が認知されたのも、その現れだと思います。ですから、次世代スーパーコンピュータを活用したライフサイエンス分野のソフトウェア開発においても、バイオロジーを予測可能な科学にするための情報の基盤を確立していくということが重要な課題であると考えています。
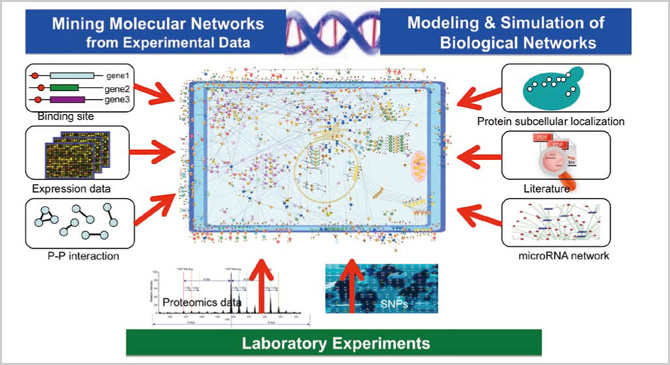
そこで、データ解析融合研究開発チームでは、「大規模遺伝子ネットワーク推定とその応用」、「大規模ゲノム多型データと表現型データを関連付ける新規アルゴリズムの開発と、妥当性、有用性の検討」、「大規模タンパク質ネットワーク推定とその応用」、「生命体シミュレーションのためのデータ同化技術の開発」という4つのグループに分かれて、各グループ間の相乗効果を発揮しながら、遺伝子の発現データなどから分子の相互作用のネットワークを解析し、その抽出モデルにダイナミクスを推定して加え、よりよいモデリングをするための方法を開発する研究開発に取り組んでいます。
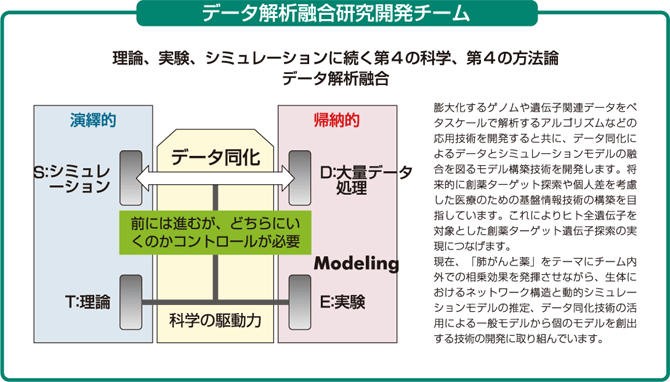
研究開発のストーリーを簡潔に説明しておきましょう。まずは、遺伝子発現データなどから、大規模な分子のネットワークを計算で予測します。そして、それを「地図」として用いて、薬や病気に関係する遺伝子や、分子間相互作用を探索していきます。地球物理学に例えて言うと、人工衛星による探査が可能になってから、全地球的な地図が簡単に入手できるようになり、温度や湿度などの状態も常に把握できるようになりました。同じようにライフサイエンス分野でも、DNAチップによって、特定の細胞の遺伝子の発現状態が一目で理解できるようになりました。これを使って、どの分子が他のどの分子とどのような相互関係にあるのかというネットワークを明らかにしていきます。つまり、動的なネットワークの「地図」をつくっていくわけです。さらに、ある病気の遺伝子がこの「地図」のどこにあるか、分子間相互作用が「地図」のどこにあるのかを見ていき、より詳しい動的ネットワークの「地図」をつくっていきます。そうすることで、より精緻なモデルが構築できるわけです。ただし、実際の人体ではバリエーションが非常に多く、常に一般的なモデルと合致するわけではありません。そこで、データ同化という技術を用います。分子生物学的に証明されたファクトや、膨大なデータからつくられたネットワークやダイナミクスを基に構築された一般モデルに、個人個人のデータを取り入れて、パーソナライズされた地図をつくり出そうというわけです。
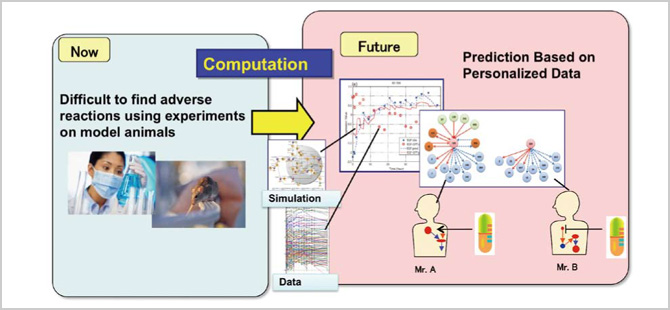
大切なのは、バイオロジカルにきちんとした裏付けのある一般モデルが構築されていれば、たとえバリエーションがあっても、個人のデータを取り入れることによって、その人のモデルをつくることができるということです。個人のモデルを最初からテーラーメイドでつくろうとしたら何年かかるか分かりませんが、データ同化によってその人のモデルができれば、シミュレーションによって、どんな薬を投与すればよいかという治療の道も開けるわけです。
私たちは、こうしたシミュレーションという演繹的なものと大量データ処理という帰納的なものをデータ同化によって融合させた「データ解析融合」という新しい手法を、理論・実験・シミュレーションに続く「第4の科学」、あるいは「第4の方法論」と位置付けています。また現在は、「肺がんと薬」をテーマに取り上げて、確率変数をモデルに取り入れてシミュレーションを行う状態空間モデルと呼ばれる手法によって、一般モデルから個のモデルを創出する新しい技術開発にも取り組んでいます。
BioSupercomputing Newsletter Vol.1
- SPECIAL INTERVIEW
- 生命現象の本質に迫る革新的なアプローチ バイオスーパーコンピューティングによる挑戦が始まる
次世代計算科学研究開発プログラム 副プログラムディレクター 姫野 龍太郎
- LEADER’S TALK
- 生命活動の基礎となる生体高分子が担う機能をシミュレーションによってとらえる
分子スケール研究開発チーム チームリーダー 木寺 詔紀 - 三次元的に人体の全身モデルを構築して生体内で起こる現象を理解し、医療に役立てる
臓器全身スケール研究開発チーム チームリーダー 高木 周 - 第4の方法論「データ解析融合」によってバイオロジーを予測可能な科学へと導く
データ解析融合研究開発チーム チームリーダー 宮野
- 研究報告
- レプリカ交換分子動力学法によるアミロイド前駆体蛋白質の膜貫通部位の二量体構造予測
分子スケール研究開発チーム 宮下 尚之 /理化学研究所 基幹研究所 杉田 有治 - 重粒子線治療シミュレーション
臓器全身スケール研究開発チーム 石川 顕一 - ゲノムワイド関連解析と遺伝的、非遺伝的要因による治療予後予測の展望
理化学研究所ゲノム医科学研究センター 鎌谷 直之 - ペタスケールコンピューティングを支える基盤技術
生命体基盤ソフトウェア開発・高度化チーム 小野 謙二 / 伊東 聰 / 渡邉 大介
- ワークショップ報告
- VPHとのジョイントワークショップを開催