

ゲノムワイド関連解析と
遺伝的、非遺伝的要因による治療予後予測の展望

理化学研究所ゲノム医科学研究センター
(データ解析融合WG)
鎌谷 直之
ヒトゲノムが2003年に解明されて以来、ゲノム配列の個人差と形質との関連についての研究が急速に進んでいます。形質とは、「ある病気になる、ならない」、「ある薬が効く、効かない」など、個人ごとに異なって観察される性質のことです。メンデル型遺伝病では、十分な家系情報さえあれば、ほぼ確実に原因遺伝子が特定できる「連鎖解析」という手法が確立しました。最初の連鎖解析は、フィッシャーが自身の開発した最尤法という数学的手法を用い1922年に発表しましたが、ヒトゲノム上の多数のマーカーの開発と、コンピュータの性能の向上ともに瞬く間に遺伝病の解明に応用されました。
研究者の興味は、次に多因子形質に向かいました。多因子形質は、メンデル型の遺伝形式を取らず、複雑な遺伝形式をとる形質であり、複数の遺伝子と環境が形質に影響すると考えられています。形質には質的形質(多くは二つの表現型を持つ)と量的形質がありますが、複数の遺伝子と環境が量的形質、質的形質に与える影響の形式は、1918年にフィッシャーにより相加的ポリジーンモデルとして定式化されています。これに基づき、現在、ヒトゲノム上の多数のマーカー(50万-100万)のデータを用いた関連解析が進行中です。この手法はゲノムワイド関連解析(genome-wide association study ; GWAS)と呼ばれ、多因子形質の遺伝的原因を解明する有力な手法です。GWASは2002年に理化学研究所ゲノム医科学研究センター(当時は遺伝子多型研究センター)が世界で最初に成功させた方法です。
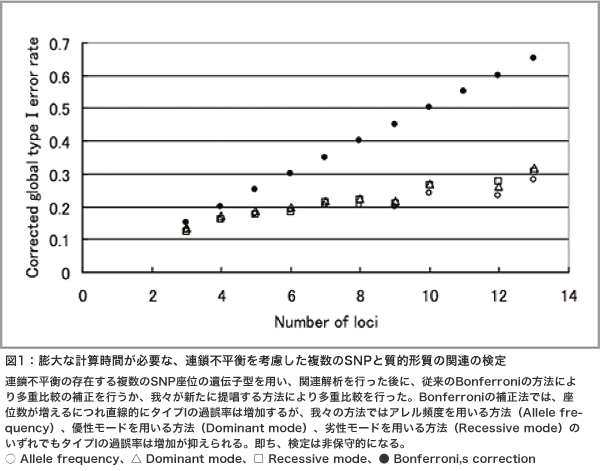
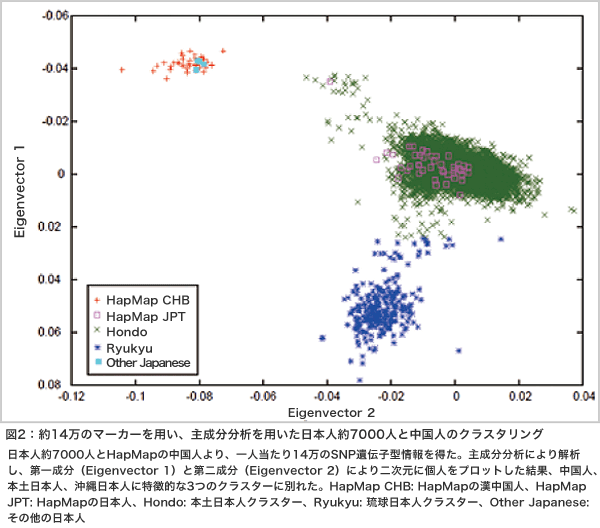
GWASで、第一に重要な作業はデータのクリーニングです。個人で数十万、それが数百、数千の人々から得られる。そのデータのクリーニングは大変な作業です。第二に重要な作業は形質とゲノム多様性との関連の有無を調べる、検定ですが、数十万回の検定を行うため、多重比較の問題が生じます。通常のP < 0.05では十分とは言えず、10-7 – 10-8レベルのP値が必要です。我々は連鎖不平衡を考慮して多数のマーカーを用いて関連解析を行うためのアルゴリズムを構築し発表しました(図1)。また、集団の構造化が存在し、それが偽陽性を与える場合があるため、その解析が重要です。我々は、主成分分析により、日本人が明確な2つのクラスター(本土と琉球クラスター)に分かれること、本土に住む人々の間でも、住む地域により大きな遺伝的違いがあることを発表しました(図2)。第三に重要な作業は種々のパラメータの推定と結果の解釈です。最終的に、種々の解析データを用いて疾患の発症予測、薬物反応性の予測を行うアルゴリズムを作成し、その評価を行います。
以上の各ステップはそれぞれ重要ですが、かなり計算時間がかかるステップが多いのが特徴です。しかも対象人数、対照マーカーの数が増えるほど計算時間がかかります。通常は、各遺伝子、環境因子の影響を独立と仮定して計算を行いますが、ここに相互作用を考慮すると計算時間は更に延長します。最近では超高速シークエンサーが現れ、一人から得られるゲノムデータの大きさは更に飛躍的に拡大しています。つまりデータはあるが計算に時間がかかりすぎて問題が解決しないのです。ペタフロップスコンピュータが使えるようになれば、現在見つからない病気の遺伝的原因も見つかるようになることは間違いありません。
このように膨大な数のデータが得られても通常、予測精度はそれほど高くなりません。その理由は、確率が安定していないからです。しかし、遺伝継承法則における確率は極めて安定しており、それがゲノムデータを用いた治療予後予測の精度を支えています。
BioSupercomputing Newsletter Vol.1
- SPECIAL INTERVIEW
- 生命現象の本質に迫る革新的なアプローチ バイオスーパーコンピューティングによる挑戦が始まる
次世代計算科学研究開発プログラム 副プログラムディレクター 姫野 龍太郎
- LEADER’S TALK
- 生命活動の基礎となる生体高分子が担う機能をシミュレーションによってとらえる
分子スケール研究開発チーム チームリーダー 木寺 詔紀 - 三次元的に人体の全身モデルを構築して生体内で起こる現象を理解し、医療に役立てる
臓器全身スケール研究開発チーム チームリーダー 高木 周 - 第4の方法論「データ解析融合」によってバイオロジーを予測可能な科学へと導く
データ解析融合研究開発チーム チームリーダー 宮野
- 研究報告
- レプリカ交換分子動力学法によるアミロイド前駆体蛋白質の膜貫通部位の二量体構造予測
分子スケール研究開発チーム 宮下 尚之 /理化学研究所 基幹研究所 杉田 有治 - 重粒子線治療シミュレーション
臓器全身スケール研究開発チーム 石川 顕一 - ゲノムワイド関連解析と遺伝的、非遺伝的要因による治療予後予測の展望
理化学研究所ゲノム医科学研究センター 鎌谷 直之 - ペタスケールコンピューティングを支える基盤技術
生命体基盤ソフトウェア開発・高度化チーム 小野 謙二 / 伊東 聰 / 渡邉 大介
- ワークショップ報告
- VPHとのジョイントワークショップを開催