

Attempting a Petascale Simulation in the K Computer Environment!
Development of New Fluid-structure Interaction Analysis (ZZ-EFSI)
Resulting in Rapid Achievement of High Operation Performance

Research Associate Professor, School of Engineering, The University of Tokyo
Kazuyasu Sugiyama
●Reviewing algorithms for establishing a new analytical method
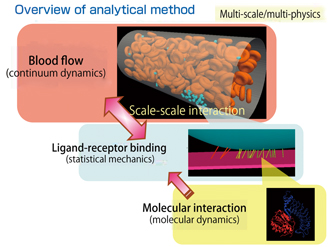
The development of fluid-structure interaction analysis has been promoted mainly in the manufacturing field. Unlike machine parts, the living body is not created according to an original blueprint. The starting point of development of the application was thus the desire to establish a unique fluid-structure interaction analysis that was fully compatible with the medical images created by CT scanning and MRI, and allowed simultaneous handling of fluids and solids that were different in mathematical expression of stress characteristics. By taking this approach, we attempted to develop an application that can be easily used in the healthcare setting and contributes to understanding of the very essence of life, clarification of disease mechanisms, and drug discovery.
For this purpose, we made efforts to develop a new analysis technique based on the Eulerian method that does not require the process of mesh generation and reconstruction. We took the formulation approach so that all the physical quantities can be updated on the fixed mesh by utilizing voxel data. In this manner, we attempted to easily simulate problems with complicated geometry and those containing many dispersed objects. Because this method facilitates expansion of computation scale, it is suitable for massively parallel computation. We also re-created a timeintegration algorithm. Recently, researchers have widely reviewed the pseudo-compressibility method that enables completely explicit time integration. We introduced dynamic parameters into this method, and perform optimization processing for minimization of velocity divergence to achieve higher effective performance and parallel scalability with numerical stability. The intention behind these developments was that they would like to achieve uniformity of operation quantity per node as much as possible, and make the most of the performance of the K computer by avoiding iterative processing.
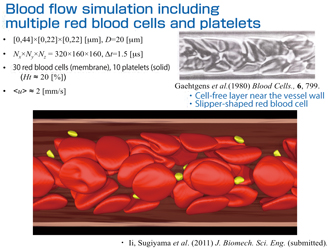
Because the computational technique developed is substantially different from conventional interaction analysis, its validity needed to be verified. A high level of reproducibility was confirmed by making a comparison with the computational results of previous fluid-structure interaction problems and fluid-membrane interaction problems that had been sufficiently verified. When we attempt to numerically handle a multimedia system in which the physical quantity jumps at the interface, we often encounter collapse of the conservation law. However, we examined our problem focusing on the budget of kinetic energy transport, and confirmed that its conservation requirement was sufficiently met. Moreover, it is important to make a comparison with actual experimental observation. For example, in the examination of the behavior of red blood cells in a fine vessel, a phenomenon of axial accumulation occurs. This phenomenon leads deformed red blood cell groups to the central axis of the vessel. We confirmed that our simulation results also clearly reflected such behavior of red blood cell groups (cell free layer near the vessel wall) and their shape (slipper-shaped red blood cell).
Currently, we are engaged in the development for practical application and extension of this new method to thrombus simulation. First, we attempted to numerically predict the process of platelet thrombus, or how a platelet attaches to the injured vessel wall. We have already developed part of a blood flow analysis simulation at the continuum level. When we try to figure out platelet attachment, we should consider the bond formation between proteins, in other words, a molecular phenomenon with fluctuation that is definitely different in scale. Because of the extremely large difference in scale, we do not directly approach the phenomenon on the molecular scale, but adopt a method that enables stochastic handling of the effect of fluctuation when observed on the continuum scale. Specifically, whether a platelet attaches or not can be expressed by the ligand receptor binding. We use a model statistically reflecting this molecular scale effect. We have been engaged in development of analytical methods based on such multi-scale multi-physics. Since we have nearly completed preparations for the new project, we would like to expand the scale and actually operate the K computer to analyze the process through which platelet attachment occurs in a vessel filled with many red blood cells.
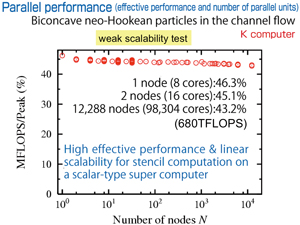
●Achievement of about 46% of the peak computation performance
We started to use the K computer, which is being increasingly used for practical computation, this year. Now, a scalar-type super computer is said to be unsuitable for fluid analysis. For example, it is said that with a fluid application for which the effective performance using the “Earth Simulator” of a vector-type super computer is about 70%, only about onetenth of the performance can be realized with a scalartype super computer. For this reason, our first goal was 10% performance. However, we made efforts to effectively utilize the functions of the K computer and elicit its high computation performance. Consequently, we succeeded in achieving a peak computation performance of about 46% in the K computer environment. We are satisfied with this relatively reasonable result. Although the K computer is a scalar-type super computer, it incorporates the hardware idea that is common to a vector-type super computer. Therefore, this result was predictable, but we can honestly say that all our efforts have been rewarded.
One of the advantages of the K computer is its high communication speed. The hardware reduction processing is a particularly important strength of the K computer. Communication may be adjacent or global communication. When we attempt to estimate the residual error in the entire field, we need the reduction processing for adding up the error at each node. In this case, global communication is realized. The present pseudo-compressibility method also requires reduction processings. The percentage of computation time needed for global communication increases with the increase in the number of nodes. At the beginning we were not able to predict the exact rate of increase, and speculated that this point would be a bottleneck for our code. In the practical setting, however, we succeeded in high-speed processing. Global communication actually accounts for less than 1% of computation time at the current operation level of about 100,000 cores. Adjacent communication accounts for 3-4% of computation time, thus showing that the transmission speed was higher than expected. We expect that the communication will be within the range of about 8% even if we use 80,000 nodes and 640,000 cores.
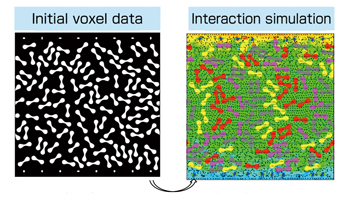 |
Fig.: Characteristics of Euler method |
 |
 |
The K computer adopts the innovative network structure called a six-dimensional mesh/torus net work interconnect (Tofu). Its adoption has contributed toward saving internode communication time. The photo shows the conceptual model of Tofu. |
●Results of practical use of K computer
We are engaged in continuum dynamics characterized by relatively simple principles and concepts. The parts to be described in codes in continuum dynamics are also quite simple. As the principles and concepts would be extremely complicated in some research fields, our results with the K computer and our attempt to generate higher performance might not be widely applicable, but some of our experiences would be informative.
We first directed our attention to the hardware monitor information by theprofiler so that we could identify the problems and improve performance. This information enables display of effective performance by loop and the speed of communication with the memory. In this manner, we can identify where the problem (hotspot) exists. The manual always instructs users to “identify the hotspot and cope with it,” and we followed this common formula and started to improve the hotspot. We adopted this restricted approach to each loop on the one hand, and a comprehensive approach to the entire program flow on the other. Thus, we reviewed the program by integrating the processing divided into several parts, or alternatively dividing the processing into several parts. It seems that a developer familiar with these code flows is the only person who could complete this task. The work may result in remarkable improvement in performance, and actually, the performance was increased in a very effective manner. A different member of our group wrote the code from the beginning to ensure cross-check. Although this approach appears to be a roundabout way, it solves the problem efficiently, and effectively promotes rapid development. As there are various types of code in the tuning stage, this resulted in many advantages. For example, we can reveal invisible problems and recognize merits by making a comparison between profiler results. As a result of continuously taking such a conservative approach, we were able to successfully enhance the application performance.
We are using Fortran, and we believe that we made the right choice. While some researchers say Fortran is out of date, the HPC compiler that a manufacturer first procures is generally Fortran. C, which would be more capable than Fortran, requires more effort for completion of the compiler. On the other hand, Fortran, within its limited ability, can easily complete a high-performance compiler. In the early stage of introduction of the K computer, writing codes with Fortran allows a higher degree of optimization and acquisition of more information than writing codes with C.
Logical thinking is of prime importance in increasing performance. A user of the K computer needs to be familiar with a hardware composition with a stratified structure. However, we can not find the best answer if we take the logical approach alone. We occasionally use logic and speculate that “this action should result in a successful outcome,” but encounter a tradeoff, resulting in failure. In this case, we should try to progress only through trial and error. It is unfavorable to aim at creating a high-quality finished program in the first trial. I think more attention should be directed to an approach that enables writing of programs in a manner that allows trial and error.
Note: The K computer is currently in the process of development. The numerical data included in this article are those obtained to date.
Acknowledgment: The data on computation with the K computer reflect the results of its experimental use.
 |
 |
BioSupercomputing Newsletter Vol.6
- SPECIAL INTERVIEW
- Development of New Fluid-structure Interaction Analysis (ZZ-EFSI) Resulting in Rapid Achievement of High Operation Performance
Research Associate Professor, School of Engineering, The University of Tokyo Kazuyasu Sugiyama - Interview with High-performance Computing Team Members: Continued Efforts in Tuning to Harness the Potentials and the High Capability of the K Computer
Group Director of Computational Molecular Design Group,
Quantitative Biology Center, RIKEN
Makoto Taiji
Senior Researcher of High-performance Computing Team,
Integrated Simulation of Living Matter Group,
Computational Science Research Program, RIKEN
Yousuke Ohno
Senior Researcher of High Performance Computing Development Team,
High Performance Computing Development Group,
RIKEN HPCI Program for Computational Life Sciences
Hiroshi Koyama
Researcher of High-performance Computing Team,
Integrated Simulation of Living Matter Group,
Computational Science Research Program, RIKEN
Gen Masumoto
Research Associate of High-performance Computing Team,
Integrated Simulation of Living Matter Group,
Computational Science Research Program, RIKEN
Aki Hasegawa
- Report on Research
- Functional Analysis of Multidrug Efflux Transporter AcrB by All-Atom Molecular Dynamics Simulation
Graduate School of Nanobioscience,
Yokohama City University
Tsutomu Yamane,
Mitsunori Ikeguchi
(Molecular Scale WG) - Multi-scale Modeling of the Human Cardiovascular System
Computational Science Research Program,
RIKEN Liang Fuyou (Organ and Body Scale WG) - Toward a spiking neuron-level model of the early saccade visuomotor system
Kyoto University Jan Moren
Nara Institute of Science and Technology Tomohiro Shibata
Okinawa Institute of Science and Technology Kenji Doya
(Brain and Neural Systems WG) - Developing the MD Core Program for Large Scale Parallel Computing
Computational Science Research Program,
RIKEN Yousuke Ohno (High-performance Computing Team)
- SPECIAL INTERVIEW
- Pioneering the Future of Computational Life Science toward Understanding and Prediction of Complex Life Phenomena
Program Director of RIKEN HPCI Program for Computational Life Sciences
Toshio Yanagida
Deputy- Program Director of RIKEN HPCI Program for Computational Life Sciences
Akinori Kidera
Deputy- Program Director of RIKEN HPCI Program for Computational Life Sciences
Yukihiro Eguchi
- Report on Research
- Free Energy Profile Calculations for Changes in Nucleosome Positioning with All-Atom Model Simulations
Quantum Beam Science Directorate, Japan Atomic Energy Agency
Hidetoshi Kono, Hisashi Ishida, Yoshiteru Yonetani, Kimiyoshi Ikebe (Field 1- Program 1) - Estimation of Skeletal Muscle Activity and Neural Model of Spinal Cord Reflex
Information Science and Technology, The University of Tokyo
Yoshihiko Nakamura (Field1 - Program 3)
- Report
- ISLiM Interim Accomplishment Meeting in 2011
Computational Science Research Program, RIKEN Eietsu Tamura - Computational Life Sciences Classes Held in High Schools
HPCI Program for Computational Life Sciences, RIKEN
Chisa Kamada, Yasuhiro Fujihara, Yukihiro Eguchi