

Key Technology Supporting Petascale Computing



High-performance Computing Team
Kenji ONO (left)
Satoshi ITO (middle)
Daisuke WATANABE (right)
The High-performance Computing team has been researching and developing the elemental technologies and software development frameworks for the development of high-performance applications. These technologies have contributed to the "Research and Development of Next- Generation Integrated Life-Science Simulation Software," a project to significantly improve the performance of developed applications and the efficiency of software development. We are now developing a visualization system that efficiently and effectively visualizes the calculation results of large-scale simulations and helps present information on these results.
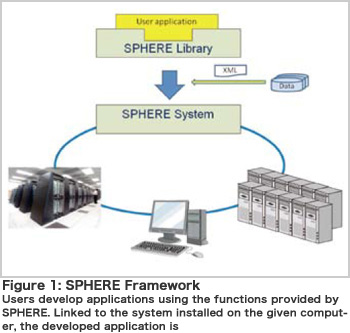
All current supercomputers are parallel computers consisting of multiple CPUs/cores. In order to achieve high performance on such computers, it is inevitable to parallelize (the distribution of input data and message passing) and optimize applications. Parallelization purely depends on programming and puts a strain on application developers. Without optimization, an application can only utilize a small percentage of the parallel computer' s performance and as a result, optimization is required to derive the full potential of parallel computers. Optimization procedures, however, differ depending on an architecture, which significantly decreases portability. To alleviate such problems in the development of a large-scale simulation system, we are developing application middleware known as SPHERE (Figure 1). SPHERE supports both the development and operation of applications. It helps with efficient development, providing various functions including data input and output, algebraic operations such as inner product calculations and boundary condition operations, etc. Every function is parallelized so that the developed application can run on a parallel computer without modification. Since each function is optimized for various computers, users can expect high performance. Aiming for higher performance, we are planning to implement auto-tuning technology to enable the system to automatically select the most appropriate method and parameters during execution. For operation, SPHERE uses XML files to describe the parameters and manage execution of each application. As a result, the same format is applied to multiple applications (for specifying analysis conditions and input/output file names, etc.) so that the operational workload decreases significantly. In addition, SPHERE provides various utilities (XML file creation support, definition of boundary conditions, domain decomposition) to improve the operational efficiency of an overall analysis. These functions are designed to improve development efficiency for industrial-use applications and aim to handle several thousand parallel processes.
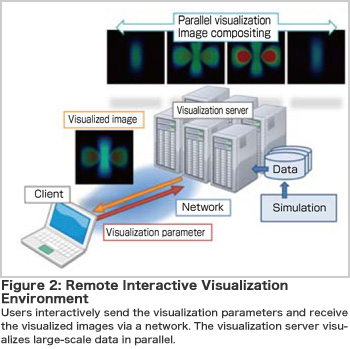
Next-generation supercomputers can perform extremely large numerical simulations and output the results as a large file group. To efficiently understand and analyze such data, we are researching and developing a functional data management and visualization system that can handle largescale data expected to reach several hundred TBs. This visualization system aims to provide an interactive visualization environment for the handling of large-scale data (Figure 2). Users can interactively specify the desired observation areas and visualization parameters and repeat visual exploration of data in real-time. This helps users have a better understanding of phenomena. The visualization system is designed as a server-client system and performs parallel distributed processing. If each node can use a GPU to create images, the visualization is faster and of better quality. To reduce the cost of loading and transferring large-scale data, we are developing the following technologies in addition to simple area selection and downsampling: Out-of-Core technology that loads only the required part of the data as necessary and fast data compression technology that achieves high compression rate. Furthermore, we provide functions for versatile use, including local visualization with a standalone PC and batch processing that visualizes data according to a pre-defined scenario. This visualization system will extract new physicochemical phenomena and useful information from large-scale simulations and contribute to scientific discoveries.
BioSupercomputing Newsletter Vol.1
- SPECIAL INTERVIEW
- Innovative Approach for Understanding Phenomena of Life Exploring New Possibilities with Bio-supercomputing
Computational Science Research Program Deputy Program Director Ryutaro HIMENO
- A Message from the Team Leader
- Simulations to Understand the Functions of the Biopolymers that Play Fundamental Roles in Life
Molecular Scale Team Team Leader Akinori KIDERA - Develop a 3-D Model of the Entire Human Body and Understand In Vivo Phenomena to Utilize for Medical Purposes
Organ and Body Scale Team Team Leader Shu TAKAGI - The Fourth Methodology (Data Analysis Fusion): Transforming Biology into a Predictable Science
Data Analysis Fusion Team Team Leader Satoru MIYANO
- Report on Research
- Prediction of Transmembrane Dimer Structure of Amyloid Precursor Protein using Replica-Exchange Molecular Dynamics Simulations
Molecular Scale Team Naoyuki MIYASHITA / RIKEN Advanced Science Institute (Molecular Scale WG) Yuji SUGITA - Simulation for Charged Particle Therapy
Organ and Body Scale Team Kenichi L. ISHIKAWA - Prospects of Prognostic Prediction Based on Genome-wide Association Study and Genetic/Non-genetic Factors
Riken Center for Genomic Medicine (Data Analysis Fusion WG) Naoyuki KAMATANI - Key Technology Supporting Petascale Computing
High-performance Computing Team Kenji ONO / Satoshi ITO / Daisuke WATANABE