

Development of Data Assimilation Technology for Simulation of Living Things

The Institute of Statistical Mathematics
Tomoyuki Higuchi (Data Analysis Fusion WG)
Through the East Japan Great Earthquake (the big earthquake that hit Eastern Japan this year), we researchers recognized that it is difficult to understand and provide protection against or control complicated systems, and that we continuously need to bring together our wisdom to solve problems. When we try to understand and control complicated systems such as the earth as well as living things, it is effective to evaluate and correct the progress of research by using our ability to predict phenomena on the assumption that information about an object is always incomplete. This approach has been demonstrated in statistics, and it has always contributed greatly to human prosperity on earth.
Prediction ability is an integrated index of effectiveness, which consists of two major functions. One of them is the descriptive power of a forward computing model, and the other is the cognitive power that catches the present state of the object (current state). To put it simply, forward computing represents a repeat assignment operation. For example, it is like a computing method where, when a value is put into the right side of an equation, the resulting value comes out of the left side, then the resulting value is also put into the right side, and the resulting value of the next step comes out of the left side. Many simulation computations explicitly solving time development adopt this method, and long-term prediction is achieved by repeating this forward computing. On the other hand, the latter is related directly to innovation of measurement methods. New instruments can provide larger amounts of more precise information than ever before by innovations with epoch-making measurement methods, and they are a great attraction to researchers in any field, especially life sciences, where new instruments have driven development.
However, leaning toward research and development of measurement devices is not a good strategy from the viewpoint of improving prediction ability. This is not only because directly measuring the whole object has limitations in theory, but it is extremely effective to strengthen the descriptive power of the forward computing model for increasing prediction ability. In the research fields that have a long history of simulation, such as earth and space sciences and solid-state physics, governing equations that are the basis of forward computing have usually been established, and it is important for success to implement calculations approximately based on the governing equations on a super computer. Improvement of this approximate calculation is equivalent to improvement of the forward computing model. One of the major goals of BioSupercomputing is to dramatically improve the descriptive power of this forward computation model by taking full advantage of the scale of computing hardware. Unfortunately, it is not an exaggeration to say that there is no principle corresponding to the governing equation in life sciences, so forward computing models themselves must be based on a wide variety of ideas and become less general.
Then, is the systematic improvement of forward computing model d ifficult in life sciences? As mentioned above, the ability to predict phenomena can be improved by enhancing both the measurement method and the forward computing model. Therefore, it looks more natural to arrange the forward computing model so that prediction ability may improve than to modify the model in accordance with its own evaluation criteria. This means that learning functions fed back from measurement data are added to the forward computing model. In fact, in the weather and oceanography fields that are state-of-the-art areas of simulation research, it is usual that weather forecasting services improve prediction performance by integrating large quantities of space data collected hourly from all over the world and the largest world scale simulated calculation result on a super computer using Bayesian statistics, and then improving simulation models in real time. Also, it has been pointed out that the simulator SPEEDI, which estimates the effects of atomic radiation and became a hot topic recently, was not able to demonstrate its power sufficiently partly because it had no function to reflect real observation data in the simulator in real time.
The integration of observation data and the result of the model is referred to as data assimilation, and it has recently been attracting attention in the field of simulation science. If the idea of data assimilation is applied to the simulation of living things, it at least will lead to a steady improvement of prediction ability, and consequently, help understanding and control of the complex system. With this fervent desire, we have worked on research and development of data assimilation technology for simulation of living things as members of the Data Analysis Fusion Team every day. Current living thing simulation models are like ready-made clothes when compared to clothes. Even if there is a variation, there might be a difference in size like S, M, and L at most. On the other hand, each human body system is different. We are looking forward to the day when a custom-made or even semicustom-made living matter simulator, which is suitable for a patient, can automatically be built from medical information about patients who suffer from side-effects of medicine or a treatment method.
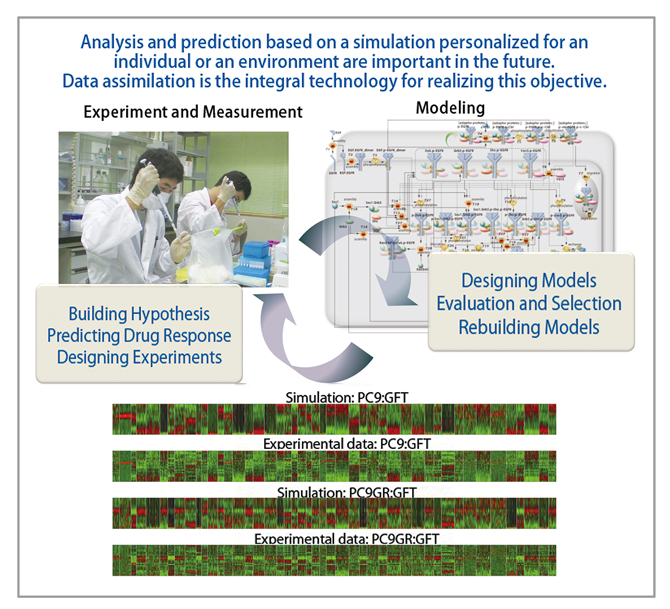
Figure 1 : Conceptual diagram that shows how to use the application under development, LiSDAS (Life Science Data Assimilation Systems). LiSDAS took its name from the well-known Automated Meteorological Data Acquisition System, AMeDAS. Data acquired from an experiment or a measurement site (upper left part) and an existing set of models (upper right part) are combined to perform the data assimilation. Data assimilation allows for evaluation and rebuilding of models at the same time. The calculation result and the measured data in the assimilated simulator are shown in the lower part. The result of the data assimilation is utilized to build a new hypothesis, and to design the following experiment. LiSDAS is such a calculation platform which achieves a series of intelligence cycles.
BioSupercomputing Newsletter Vol.5
- SPECIAL INTERVIEW
- The time has come for biosupercomputing to get results with the world's No. 1 supercomputer
"K computer", and take up the challenge of "prognostic biology".
Deputy Program Director of Computational Science Research Program, RIKEN Ryutaro Himeno - What should we do to promote industrial use of sophisticated computer resources and development applications?
Chief Coordinator of Foundation for Computational Science Masahiro Fukuda
Chief Researcher of Urban Innovation Institute and Executive Board Member and Bureau Chief of BioGrid Center Kansai Ryuichi Shimizu
- Report on Research
- Analysis of molecular mechanism of enzymatic reactions by QM/MM Free Energy Method
Graduate School of Science, Kyoto University Shigehiko Hayashi (Molecular Scale WG) - Computational Mechanobiology of Actin Cytoskeleton
Institute for Frontier Medical Science, Kyoto University Yasuhiro Inoue (Cell Scale WG) - Development of Blood flow Analysis Method for Simulation of Thrombus Formation
Department of Mechanical Engineering, The University of Tokyo Satoshi Ii (Organ and Body Scale WG) - Development of Data Assimilation Technology for Simulation of Living Things
The Institute of Statistical Mathematics Tomoyuki Higuchi (Data Analysis Fusion WG)
- SPECIAL INTERVIEW
- Pioneering the Future of Computational Life Science toward Understanding and Prediction of Complex Life Phenomena
Program Director of RIKEN HPCI Program for Computational Life Sciences Toshio Yanagida
Deputy- Program Director of RIKEN HPCI Program for Computational Life Sciences Akinori Kidera
Deputy- Program Director of RIKEN HPCI Program for Computational Life Sciences Yukihiro Eguchi
- Report on Research
- Simulation Applicable to Drug Design
Research Center for Advanced Science and Technology, The University of Tokyo Hideaki Fujitani (Field 1- Program 2) - An Ultra-fast Analysis System for Next-Generation DNA Sequencer Data
Graduate School of Information Science and Engineering, Tokyo Institute of Technology
Yutaka Akiyama, Takashi Ishida, Masanori Kakuta, Shuji Suzuki (Field 1- Program 4)
- Report
- BioSupercomputing Summer School 2011
Computational Science Research Program, RIKEN Yasuhiro Ishimine (Organ and Body Scale WG)
Research and Development Center for Data Assimilation, Institute of Statistical Mathematics Masaya Saito (Data Analysis Fusion WG)
Niigata University of International and Information Studies Eisuke Chikayama (Cell Scale WG)
School of Medicine, Tokai University Yohei Nanazawa (Cell Scale/Organ and Body Scale WG)
Computational Science Research Program, RIKEN Takashi Handa (Brain and Neural Systems WG)
Computational Science Research Program, RIKEN Gen Masumoto (High-performance Computing Team)
Computational Science Research Program, RIKEN Kei Moritsugu (Molecular Scale WG) - “Next-Generation Integrated Simulation of Living Matter (ISLiM)”, a web page dedicated to new applications, has opened.
Computational Science Research Program Integrated Simulation of Living Matter Group
- Event information