

High-performance Computing Team
High-performance Computing
Environment to Maximize the Potential
of the Next-generation Supercomputer

High-performance Computing Team
Team Leader
Makoto TAIJI
The key role of the High-performance Computing Team is to boost the performance of applications and to establish a platform to support the industrial use of applications from the perspective of high-performance computing and mathematical engineering. In other words, our job is to optimize the applications developed by other teams for the next-generation supercomputer to help the research and development in the Next- Generation Integrated Simulation of Living Matter.
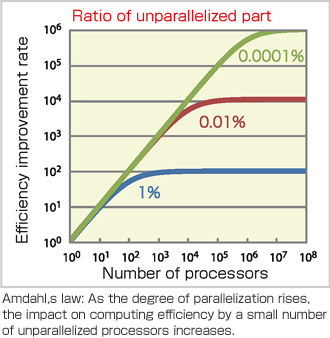
The next-generation supercomputer is an unprecedentedly massive parallel computer that will consist of more than 80,000 processors, 640,000 cores and 5 million arithmetic units. To maximize its potential, it is indispensable to develop software that operates on the supercomputer as efficiently as possible. To realize it, the deep-parallelization far beyond the level of parallelization used in current parallel computers, which usually consist of 100 or 1,000 processors, is now required. Among the models that represent the rate of efficiency improvement expected from parallel computing, “Amdahl’s law” is known as the simplest one. In accordance with this law, the rate of efficiency improvement is estimated by the proportion of the part of a program that can be executed in parallel to the part that cannot be executed in parallel. Obviously, if the ratio of the parallelizable part is small, computing speed cannot be improved even if many processors are used. When 1,000 processors are used, computing performance will degrade if the non-parallelizable part exceeds 0.1%. When it comes to 10,000 and 100,000 processors, the ratio shrinks to 0.01 and 0.001%, respectively. In this manner, the ratio reaches an advanced digit, 0.0001%, with the next-generation supercomputer. In other words, almost perfect parallel computing of 99.9999% is required. To achieve this, we must make every effort, including the introduction of state-of-the-art knowledge in computer science and further modify the algorithms based on the knowledge of applications. That is where the significance of our team’s existence lies.
One of the key issues is how to boost the efficiency of communication, where data is transmitted between computing nodes. Such factors as network composition, which are essential factors for our goal, depend on the details of hardware. Therefore, we are aiming at developing optimum software by going as far back as detailed information on the hardware. As specific challenges, we are addressing support for massive parallel computing and the development of core software, as well as common infrastructure libraries and visualization software, etc., with a view to realizing higher-performance applications (See Report on Research of BioSupercomputing Newsletter Vol. 1 for the common infrastructure libraries and visualization software).
We are currently evaluating each team's representative application as their first endeavor. Each application's bottlenecks for massive-parallel computing are understood gradually now. We will report on how their performance can be improved along with our evaluations and collaborating with developers from now on. In the field of life science, I feel that there still remains a distance between the computational goal of the maximum utilization of the next-generation supercomputer and the scientific goal of solutions to actual problems. We are planning to discuss these issues with the project members and consider not only how to simply advance parallel computing, but also how we can achieve the maximum scientific results by most effectively leveraging computational resources. In addition, we consider that it is also an important function of our team to make information on hardware and operational constraints easy to understand and pass it on to developers. After the next-generation supercomputer actually starts operating, we should consider on the targets appropriate for the machine, while feeding back what problems and solutions can bring about higher performance to the user side. As we cannot know many aspects of the supercomputer until we actually run it as its parallel computing extends to such a massive scale, we believe that it is also one of our functions to convey expertise such as "usability."
While supporting each application, our team is currently developing the "MD (molecular dynamics) core program for massively parallel computing" at the same time. Raising the efficiency of each team's applications is of course an important challenge, but we have to build up our expertise in massively parallel computing in the first place. We also have another goal of verifying the next-generation supercomputer's parallel computing efficiency. Therefore, we are addressing this challenge to establish the art of computing for simulating the function of proteins at a high speed for many hours.
It can probably be said that other research and development teams are in their busiest phase now when they are advancing application software development, but our team feels that we will enter our busiest phase from now when the next-generation supercomputer actually starts operating. At the phase, probably we will face a number of challenges that we must tackle or haven't even thought about.
BioSupercomputing Newsletter Vol.2
- SPECIAL INTERVIEW
- Aiming to Become a Global Trendsetter in the Life Sciences by Making the Best Use of the Next-generation Supercomputer!
Computational Science Research Program Deputy Program Director
Ryutaro HIMENO
- A Message from the Team Leader
- Simulating Cell Phenomena by Recreating Cells as They Exist in Living Organisms
Cell Scale Team Team Leader
Hideo YOKOTA - Create a Brain on a Supercomputer to Unravel the Functions of the Brain and Nervous System
Brain and Neural Systems Team Team Leader
Shin ISHII - High-performance Computing Environment to Maximize the Potential of the Next-generation Supercomputer
High-performance Computing Team Team Leader
Makoto TAIJI
- Report on Research
- Protein Reaction Simulation Based on All-electron Calculation
Institute of Industrial Science, the University of Tokyo
Fumitoshi SATO / Toshiyuki HIRANO / Noriko UEMURA / Naoki TSUNEKAWA / Junichi MATSUDA - Full Eulerian Fluid-structure Coupled Method
Associate Professor at School of Engineering, the University of Tokyo
Kazuyasu SUGIYAMA - A Large-scale Simulation Model of Cortical Microcircuits: CMDN(Cortical Microcircuit Developed on NEST)
Brain and Neural System Team
Jun IGARASHI - Development of Next-generation Molecular Dynamics Simulation Programs
High-performance Computing Team
Hiroshi KOYAMA / Yosuke OHNO / Gen MASUMOTO / Aki HASEGAWA / Gentaro MORIMOTO