

「京」環境で ペタスケール・シミュレーションにチャレンジ!
新しい流体構造連成解析手法(ZZ-EFSI)の開発によって
いち早く高い演算性能を達成

東京大学大学院工学系研究科特任准教授
杉山 和靖
●アルゴリズムも見直し、新たな解析手法を確立
構造解析手法は、これまで主にものづくり分野で開発が進められてきました。しかし、機械部品などとは違い、生体にはもともと設計図が存在しません。そこで、CTやMRIによる医療画像と相性がよく、応力特性の数理的表現が異なる流体と固体を一緒に扱えるような、これまでにない流体構造連成解析を実現したい、それがアプリケーション開発の出発点でした。それによって、医療現場で使いやすく、生命現象の本質の理解、病気のメカニズム解明、さらには創薬にも貢献できるものにしたいと考えてきました。
そのために取り組んだのが、メッシュの生成・再構築というプロセスを必要としないオイラー型の新しい連成解析手法です。ボクセルデータを利用して、固定メッシュ上ですべての物理量を更新できるように定式化することにより、複雑な境界を持つ問題や、多数の分散体を含む問題のシミュレーションを容易に実現することを目指しました。また、この方法は計算規模の拡張が容易であるため、大規模並列計算に適しています。一方で、時間積分のアルゴリズムもつくり直しました。最近、完全陽的な時間積分を実現する擬似圧縮性法が広く見直されています。それに動的パラメータを導入し、速度発散を最小化する最適化処理を行なうことによって、数値的に安定で、高い実行性能・並列性能を実現しています。これらの開発の背景には、ノードごとの演算量をできるだけ均一にするとともに、反復の多い処理を避けることで、「京」の性能を有効に活用したいという狙いがありました。
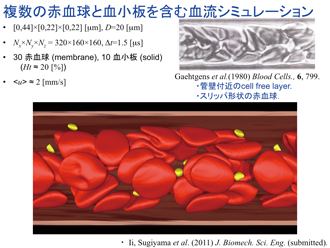
開発した計算手法は、従来の連成解析法と大きく異なりますので、その妥当性が検証されなければなりません。まず、これまでの十分に検証された流体構造連成問題や流体膜連成問題の計算結果との比較を行いましたが、非常によく再現できることを確認しました。また、界面で物理量の跳躍を伴うような多媒質の系を数値的に扱おうとすると、保存則が破綻することがよくありますが、私たちが解きたい問題の運動エネルギー輸送の収支を調べると、その保存性がしっかりと満たされることを確認しました。さらに、実際の実験観測との比較も重要ですが、例えば細い血管のなかで赤血球の振る舞いがどうなっているかというと、変形した赤血球群が血管の中心軸に集まろうとする軸集中という現象がおきます。私たちの計算結果でも、こうした赤血球群の振る舞い(管壁付近のセルフリーレイヤー)や形状(スリッパ型の赤血球)が、非常によく再現できていることを確認しました。
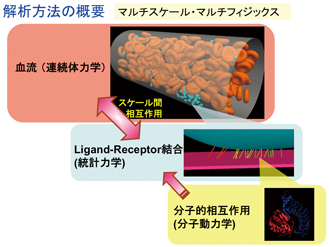
現在は、この新しい方法論を、血栓シミュレータに応用・拡張するための開発を行っています。最初に取り組んだのは、血小板血栓に至る過程、つまり血小板が傷ついた血管壁にどのように付着するのかを数値予測するということです。すでに連続体レベルの血流解析シミュレーションの部分は開発できていますが、血小板の付着を捉えようとすると、タンパク質同士の結合、言い換えれば揺らぎを持つ分子レベルの現象という、明らかにスケールが異なるものを考える必要があります。ただし、スケールの違いが大きすぎますので、分子スケールの現象を直接扱うのではなく、連続体スケールで見たときの揺らぎの効果を確率論的に扱う方法を取り入れています。具体的には、付着するかどうか、リガンド・レセプター結合と呼ばれていますが、この分子スケールの効果が統計論的に反映されたモデルを使っています。こうしたマルチスケール、マルチフィジックスを考慮した解析手法を開発してきました。ほぼ準備は整いつつありますので、今後は規模を拡大して、実際に「京」で走らせながら、多数の赤血球が存在する血管の中で、血小板の付着に至るプロセスを解析していきたいと考えています。
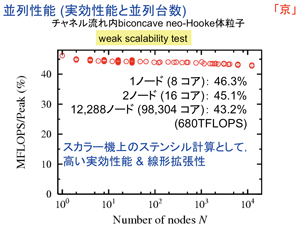
●ピーク性能の約46%の計算性能を達成
今年度から、整備が進む「京」を使った計算が始まりました。スカラー機は流体解析には向いていないと言われています。例えばベクトル機の「地球シミュレータ」で70%くらいの実効性能が出ていた流体のアプリケーションが、スカラー機では10分の1ほどの性能しか出ないといった話を聞いていました。そのため、最初は10%くらいの性能値が出れば……という気持ちでした。しかし、それでも、できるだけ「京」の機能を有効に活用して、高い計算性能を引き出すことを目指してきました。その結果、「京」環境で、ピーク性能の約46%の計算性能を出すことができました。比較的よい結果が得られたと思っています。スカラー機ではありますが、「京」はハード的にベクトル型と似たような発想がありますので、これくらい出ても不思議はないという思いもありますが、それでも、正直なところ、頑張ってきた甲斐があったという気持ちです。
「京」の優れている点のひとつは、通信のスピードが速いことです。特にハード的なリダクション処理に強みがあります。通信には隣接通信と大域通信があります。例えば場全体の誤差を評価しようとすると、各ノードでの誤差を足し合わせるリダクション処理が必要で、その場合、大域通信が発生します。今回開発した疑似圧縮性法でも、リダクション処理がいくつか必要です。大域通信は、ノード数が増えるほど計算時間に対する割合が増えますが、当初、どれくらいのペースで増えるのか分からず、私たちのコードにとってボトルネックになると思っていました。しかし、実際にやってみると高速に処理されており、大域通信の占める時間の割合は、現在やっている約10万コアで1%にも達していません。また、隣接通信は3 ~ 4%で収まっていて、予想以上に速いことが分かりました。恐らく、8万ノード、64万コアを使っても、通信は8%程度に収まるのではないかと思っています。
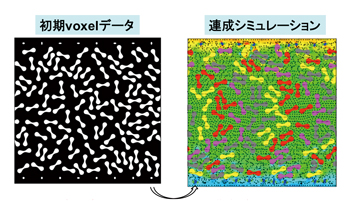 |
図:Euler法の特徴 固定メッシュ上で,全ての物理量を更新 複雑な境界形状を持つ/多数の分散体を含む 流体・構造連成問題の数値シミュレーションを容易に 境界適合メッシュの生成・再構成が不要 |
 |
|
「京速コンピュータ「京」では、6次元メッシュ/トーラス構造ネットワーク(Tofu)という革新的なネットワーク構成を採用。ノード間通信の時間短縮に貢献している。写真はTofuの概念模型」 |
●実際に「京」を使ってみて思うこと
私たちが取り組んでいる連続体力学というのは、原理原則が比較的単純で、コードで記述する部分も非常にシンプルです。研究分野によっては原理原則がとても複雑な場合もあるでしょうから、私たちの「京」を使った感想や、より高い性能を出すための取り組みは、必ずしも一般的に通用するとは限らないのですが、いくつか気付いたことをお話します。
問題点を見つけ出したり、性能を高めていくために、私たちが最初に注目したのは、プロファイラーによるハードウェアモニタ情報でした。これによって、ループごとの実効性能や、メモリーとのやり取りのスピードなどが示され、どこに問題点(ホットスポット)があるかを見つけることができます。「ホットスポットを見つけて対処する」ことはマニュアルにも記されている常套手段でして、まずはそこに手をつけました。これはループ毎に対する局所的な対処法ですが、一方で大局的にプログラム全体の流れを見て、いくつかに分割化されている処理をまとめたり、逆に分割するといった見直しも行いました。これらはコードの流れを理解している開発者でないと対処が難しいように思いますが、大幅な性能向上をもたらす場合があり、非常に効果的でした。また、私たちのグループでは、別の方に1からコードを書いてもらい、クロスチェックを行なってきました。回り道のようですが、問題を効率的に解決するには重要で、迅速に開発を進めるのに有効だと思います。さらにチューニングに際しては、何種類もコードが存在することになりますので、プロファイラの結果を比較することで、見えなかった問題点が明らかになったり、逆によいところが見えてくるなど、いろいろな効果がありました。こうしたことを地道にやり続けていくことによって、アプリケーションのパフォーマンスを高められたのだと思います。
私たちはFortranを使っていますが、結果的にそれがよかったという実感も持っています。Fortranは古いという人もいますが、メーカーがHPC用のコンパイラでまず何を準備するかというと、普通はFortranでしょう。CはFortranに比べてできることが多いでしょうが、それだけ整備するのは大変です。その点、Fortranはできることに制約がありますが、その範囲内で性能の高いコンパイラを完成させることは簡単なわけです。「京」が整備されていく初期段階では、CよりもFortranで書く方が、より最適化され、情報も多く得られたように思います。
性能を上げるために何よりも重要なことは、理詰めで考えていくということでしょう。「京」の場合には、階層的な構造を持つハード構成を理解することです。ただし、理詰めで考えるだけでは、ベストな答えを見つけるのは困難です。論理的に「こうすればうまくいくはず」と対処しても、どこかにトレードオフがあって逆効果になることがよくあります。その場合には、試行錯誤しながら進めていくしかありません。そのためには、最初から完成度の高いもの一気に仕上げようとするのではなく、試行錯誤しやすいようにプログラムを書くことも、大事なポイントだと思います。
注:京は現在開発中であり、これらの数字は現状の値です。
謝辞 京での計算に関しては京速コンピュータ京の試験利用での結果です。
 |
 |
BioSupercomputing Newsletter Vol.6
- SPECIAL INTERVIEW
- 新しい流体構造連成解析手法(ZZ-EFSI)の開発によっていち早く高い演算性能を達成
東京大学大学院工学系研究科 特任准教授 杉山 和靖 - 開発・高度化チームに聞く「京」の実力と高い性能を引き出すために続くチューニングの取り組み
理化学研究所 生命システム研究センター 生命モデリングコア計算分子設計研究グループ
グループディレクター 泰地 真弘人
理化学研究所 次世代計算科学研究開発プログラム 次世代生命体統合シミュレーション研究推進グループ
生命体基盤ソフトウェア開発・高度化チーム 上級研究員 大野 洋介
理化学研究所 HPCI計算生命科学推進プログラム 高度化推進グループ
高度化推進チーム 上級研究員 小山 洋
理化学研究所 次世代計算科学研究開発プログラム 次世代生命体統合シミュレーション研究推進グループ
生命体基盤ソフトウェア開発・高度化チーム 研究員 舛本 現
理化学研究所 次世代計算科学研究開発プログラム 次世代生命体統合シミュレーション研究推進グループ
生命体基盤ソフトウェア開発・高度化チーム リサーチアソシエイト 長谷川 亜樹
- 研究報告
- 全原子分子動力学シミュレーションによる多剤排出トランスポーターAcrBの機能解析
横浜市立大学大学院生命ナノシステム科学研究科 山根 努 / 池口 満徳( 分子スケールWG) - ヒト循環器系のマルチスケールモデリング
理化学研究所 次世代計算科学研究開発プログラム 梁 夫友( 臓器全身スケールWG) - 初期サッカード視覚運動系のスパイキングニューロンレベルでのモデル化
京都大学 ジャン・モーレン
奈良先端科学技術大学院大学 柴田 智広
沖縄科学技術大学院大学 銅谷 賢治
(脳神経系WG) - 大規模並列用MDコアプログラムの開発
理化学研究所 次世代計算科学研究開発プログラム 大野 洋介(開発・高度化T)
- SPECIAL INTERVIEW
- 複雑な生命現象の理解と予測に向けて計算生命科学の明日を拓く
理化学研究所 HPCI計算生命科学推進プログラム プログラムディレクター 柳田 敏雄
理化学研究所 HPCI計算生命科学推進プログラム 副プログラムディレクター 木寺 詔紀
理化学研究所 HPCI計算生命科学推進プログラム 副プログラムディレクター 江口 至洋
- 研究報告
- 全原子モデルにもとづくヌクレオソームポジション変化の自由エネルギープロファイル計算
日本原子力研究開発機構 量子ビーム応用研究部門
河野 秀俊 / 石田 恒 / 米谷 佳晃 / 池部 仁善
(分野1-課題1) - 骨格筋の活動の推定と脊髄反射の神経モデル
東京大学情報理工学系研究科 中村 仁彦(分野1-課題3)
- 報告
- ISLiM 成果報告会2011
理化学研究所 次世代計算科学研究開発プログラム 田村 栄悦 - 高等学校で行った計算生命科学の授業
理化学研究所 HPCI計算生命科学推進プログラム 鎌田 知佐 / 藤原 康広 / 江口 至洋