

バイオスーパーコンピューティングが拓くライフサイエンスの未来
「京」への展開で、実利用に向けた最適化とさらなる規模の拡張を進める
大規模仮想ライブラリ

東京大学大学院工学系研究科 化学システム工学専攻 教授
船津 公人
●創薬開発のカギとなる化合物ライブラリの現状
新薬の開発期間は十数年という長期間に及び、医療現場まで送り出される確率は数万分の1ともいわれています。そのため、開発コストも研究開発リスクも極めて高いのが実情です。こうした新薬の開発は、薬物標的の同定からスタートし、リード化合物を見つけ出し、それを最適化して活性をいいところまで持っていく、それからは臨床試験という流れになりますが、全体のなかで、成否のカギを握っているのは、化合物ライブラリからのリード化合物のスクリーニングに端を発する、初期段階の的確なリード化合物群の捕捉です。保有する化合物ライブラリの化学的な多様性と質、そして規模が、製薬会社の潜在的な開発能力を決定づけるといわれているのもそのためです。
では、化合物ライブラリの現状はどうなっているかというと、創薬研究の対象となる化合物の理論的な総数は10の60乗と推計されています。これに対して、製薬会社(メガファーマ)が保有する実在化合物のライブラリ数は、わずかに数百万化合物でしかなく、スクリーニングでヒットしなかったり、低活性の化合物しか得られなかったりと、漏れの大きさが常に問題になっています。こうしたことから、スクリーニングのヒット率向上のためにも、化合物ライブラリの規模と多様性が強く求められ、より可能性のある化合物を網羅的に探索するという見地から、計算機上に構築されたバーチャルライブラリ(仮想化合物群)の活用に大きな期待が寄せられています。しかし、すでに存在するバーチャルライブラリを調べてみると、その備蓄件数は多くても数千万化合物程度であり、理論的総数と比較すれば、微々たるものでしかありません。これでは、いくらスクリーニングしても、ケミカルスペースのほんの一部分しか見ていないことになり、大きな助けになっていないというのが実情です。さらに、バーチャルであるがゆえに、高スコアのリード化合物群を絞り込めたとしても、それらの合成検討に大きなコストが必要になるという問題も生じています。また、仮想化合物構造の創生を、原子種の組み合わせと各原子が取り得る結合次数に基づく理論操作だけに頼ると、せっかくのライブラリも、合成不可能な不安定化合物などを多く含むものになってしまう可能性があります。
●大規模仮想ライブラリの特徴とその概要
こうした問題を解決して、仮想化合物群の質や多様性、規模などの面で満足のゆく、これまでにない新しいバーチャルライブラリを構築しようというのが、私たちが取り組んでいる「合成可能な化学構造および反応スキームからなる大規模仮想ライブラリの構築」です。ただ単に「大規模仮想ライブラリ」をつくるのではなく、「合成可能な化学構造および反応スキーム」によって構成されるライブラリであることが非常に重要です。化合物をつくるための合成経路も、一緒に含まれているわけです。もちろん、規模も大切です。私たちはドラッグライクネスと多様性を確保しながら、既存の数千万程度のライブラリを遥かに超える、10億から20億規模のバーチャルライブラリ構築をめざしています。
そのために開発したのは、42万種に及ぶ既存化合物ライブラリから、種構造を順次構造創出システムに投入し、トランスフォームという構造変換情報を適用して、新しい構造を作り出すシステムです。トランスフォームとは、反応データベースから抽出された、反応前後の反応部位の構造変化情報です。もっと分かりやすくいうと、既存の反応データベースから、各反応スキームの反応物と生成物の反応部位における結合次数の変化や構造環境変化などの情報、言い換えるなら“反応のエッセンス”を取り出して、それらを蓄積したデータベースです。
このトランスフォーム情報を適用し、反応物構造に対する生成物構造を反応スキームとして提示する順合成反応創出システムを連続運用することで、順合成ルートが付与されたバーチャルライブラリが構築されます。このバーチャルライブラリに含まれる化合物構造は、反応物構造と生成物構造との関連を保持した順合成ツリー構造を形成します。逆に、標的化合物構造に対する前駆体構造を反応スキームとして提示する逆合成反応創出システムを連続運用することで、逆合成ルートが付与されたバーチャルライブラリが構築されます。このバーチャルライブラリに含まれる化合物構造は、合成前駆体構造と反応生成物の関連を保持した逆合成ツリー構造を形成します。順合成のツリー領域であれば、反応物から生成物予測のスキームを示し、逆合成のツリー領域では、標的構造から反応部位を持つような合成前駆体を提案します。つまり、順反応方向だけでなく、何からつくればよいかという逆合成方向からの仮想化合物構造も、バーチャルライブラリに含まれることになります。
実際に既存の化合物ライブラリの種構造を投入すると、トランスフォームを適用することによって、いくつもの生成物構造の候補が出てきます。続いてそれらの生成物構造の候補を反応物構造としてトランスフォームを適用すると、さらに次の段階の生成物構造の候補が出てくる。一方では、これをつくるためには何からつくればよいかをたどっていくこともできる。また、なかには分子サイズが小さいもの、リード化合物の候補にならないと判断される、ドラッグライクネスを持たないものも出てきます。それは仮想ライブラリの検索対象にはなりませんが、合成ルートをつなぐという意味では必要な情報ですのでライブラリに含まれています。
今年度も、出力構造を再帰的に入力構造に置き換え、多段スキーム発生による規模の拡大を継続しており、バーチャルライブラリ全体として、順方向と逆方向の反応スキーム例を含めて、重複しないユニークな化合物10億件を納めることを目標にしています。さらに、その先へ延ばしたり、最初の種となる構造を追加することで、20億件のバーチャルライブラリも可能ではないかと考えています。
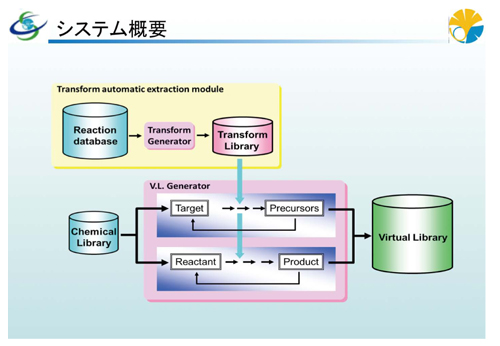 |
大規模仮想ライブラリのシステム概要 |
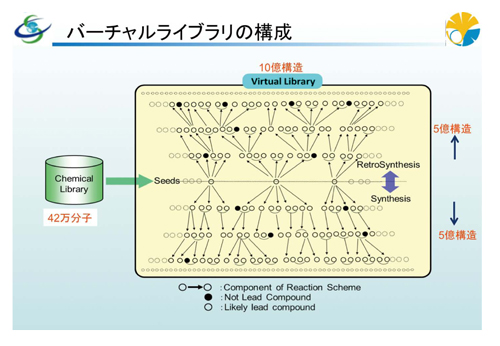 |
大規模仮想ライブラリの構成 |
●ライブラリ創出エンジンの評価
さらなる開発を続ける一方で、このバーチャルライブラリ創出エンジンの特性や出力された化合物群を把握するための評価も行っています。全てではありませんが、種構造群として利用した42万構造から1500万化合物を発生させた段階で、重複を排除したユニークな化学構造は630万種を数えました。出力化合物の重複率は58%で、半分をやや上回る程度でした。新規性については、この630万種の発生化合物群を、1500万件を含む購入可能な既存の化合物ライブラリと対比した結果、市販化合物との重複は、わずかに1.33%でしかありませんでした。したがって、このシステムによって出力された構造は、そのほとんどが新規化合物であり、新規性は十分に確保されていると判断しています。
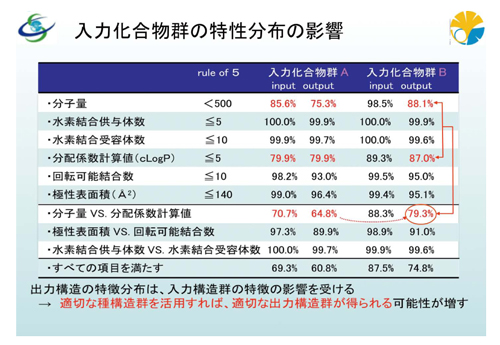
さらに、入力化合物群の特性分布の影響の検討も行っています。バーチャルライブラリは入力した種構造から発生するわけですが、その発生した化学構造が薬物として意味があるかどうかを判断する基準に、ADMIT特性(吸収、分布、代謝、排泄、毒性)があります。この特性予測を算出することによって、その化学構造を事前に評価できるわけです。例えば、経口投与された場合、体内に吸収されなければ、薬として働きません。薬は有機物で、しかも結構大きな分子量ですから、基本的に水に溶けません。したがって、当然ながら吸収されにくいわけです。それでは具合が悪いので、水に溶ける特性をある程度保持している必要があります。溶ける、溶けないだけでなく、極性表面積が大きければ溶けやすいとか、水素結合の供与体数や受容体数が多ければ溶けやすさを助長するだろうといった、いろいろな特性で評価できるわけです。そうした吸収に関して予測するための経験則が「リピンスキーの規則(ルール・オブ・ファイブ)」です。今回、この「リピンスキーの規則」に示される各特性値の分布の検討を行いました。その結果、本システムが出力する仮想化学構造は、入力化合物群の特徴を引き継ぎ、その特性値の分布を拡張しつつ、各特性値指標の適合率の高い化合物群を種とすると、指標適合率の高い化学構造群を出力することが確認できました。つまり、種構造群を適切に選択すれば、医薬品としての適性がある仮想化合物を、高い確率で出力できることを示しています。
今後は、実際に「京」の上にこの大規模仮想ライブラリを載せて、一般の利用者も含めて活用していくことになります。スクリーニングのためのソフトウェアは別のグループで開発していますので、私たちは大規模仮想ライブラリを提供していくわけです。また、ライブラリの要素となる化学構造と反応スキームを創出するためのライブラリ創出エンジンを「京」に載せておけば、今後は「京」のユーザーになる製薬会社の方々が、自分たちの所有している化合物ライブラリからバーチャルライブラリを構築させることも可能になります。このライブラリ創出エンジンそのものは、本プロジェクト以前に船津研究室で開発済みですが、希望も多いことから、今後この創出エンジンについても提供の準備をしていくことになると思います。
私たちとしては、この道具立てはほぼできたと思っています。これからはユーザーの方たちの具体的な希望なども聞きながら、実際の創薬に向けた実利用を進めていくために、今後、大規模仮想ライブラリをどのように活用していけばよいのかを考える、そうした新しいフェーズに入ったといえるでしょう。
 |
|
BioSupercomputing Newsletter Vol.7
- SPECIAL INTERVIEW
- 「京」開発担当者に聞く今後のスパコン戦略とエクサスケールに向けた取り組み
富士通株式会社 テクニカルコンピューティングソリューション事業本部
エグゼクティブ・アーキテクト 奥田 基 - 「京」への展開で、実利用に向けた最適化とさらなる規模の拡張を進める大規模仮想ライブラリ
東京大学大学院工学系研究科 化学システム工学専攻 教授 船津 公人
- 研究報告
- 水の誘電率計算から得られる古くて新しい問題
大阪大学蛋白質研究所 中村 春木(分子スケールWG) - 大規模並列計算用流体・構造連成解析プログラムの開発
理化学研究所 情報基盤センター 杉山 和靖(臓器全身スケールWG) - スーパーコンピュータを用いた大規模遺伝子ネットワーク推定ソフトウェア SiGN
東京大学大学院情報理工学系研究科 玉田 嘉紀(データ解析融合WG) - ISLiM研究開発ソフトウェアのソース・コード公開に向けた活動
理化学研究所 次世代計算科学研究開発プログラム 田村 栄悦
- SPECIAL INTERVIEW
- 「京」を用いた大規模シミュレーションによって細胞内分子ダイナミクスの理解と予測を実現する
理化学研究所 基幹研究所 杉田理論分子科学研究室 主任研究員 杉田 有治(課題1 代表) - 日本の優れたコンピュータ技術を活かして革新的な分子動力学創薬に挑戦
東京大学 先端科学技術研究センター 特任教授 藤谷 秀章(課題2 代表)
- 報告
- 大学の新入生に行った計算生命科学の講義
理化学研究所 HPCI計算生命科学推進プログラム 鎌田 知佐
- 体制
- 計算科学技術推進体制