(Updated on 2013/3/9)
Yosuke Ohno, HPC Team, CSRP, RIKEN
A fast classical MD code for highly parallel computing
Classical molecular force field, Lennard-Jones model, coulomb force
Direct summation for short distances, and FEM/PME for long distances
Domain decomposition(MPI)、loop dividing(thread parallel)
C/C++, MPI, OpenMP
Source code is available through ISLIM download site
- A 980-thousand-atomic system with 8,000 cores of RIKEN RICC
- For 1,000 steps, 5.1 sec (4.5 sec for communication)
- Required memory/disk storage: 1.2 TB/0.1 TB
- Submilli-second simulations (>109 steps) for a 1-million-atomic system
- Required memory/disk storage: 10 TB/100 TB.
Figure 1. A massively parallel large-scale MD computing.
- Massive parallel MD computing with more than 640 thousands of cores
- A longer time scale (sub-msec) simulation for 1 million atomic system of a biomolecule
- Simulation accuracies enough to apply to the drug discovery as well as to understand the principals of life systems in the atomic level.
Kenji ONO, CSRP, RIKEN
The code visualize a large volume of data from a large-scale simulation run by distributed-parallel processing. The code supports various usage styles, such as remote-visualization, standalone-visualization, interactive-visualization, batch-visualization. The client code runs on multiplatforms
MPI parallelization by the domain decomposition
- C++, MPI, libxml2, zlib
- Status of code for public release
- Source code is available through ISLIM download site.
- A hundred cores
- The number of meshes: 2450 x 1330 x 8435
- Required memory/disk storage: About 100GB
- Parallel execution with hundreds of thousands of cores
- Required memory/disk storage: 100TB/1 PB.
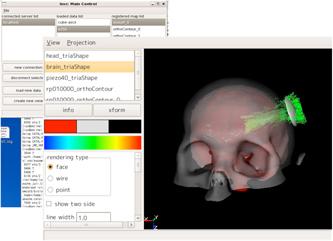
Figure 1. Visualization of the high-intensity focused ultrasound (HIFU) data for a minimally invasive therapies.
- Visualization of simulation output data that are too large to process on a PC
- Remote-visualization interactively to use the visualized results by a server, and batch-visualization to make
- Extension of the visualization function with plug-ins.
Kenji ONO, CSRP, RIKEN
The code gives an integrated development environment to promote development and operation for the continuum dynamics simulation code. The orthogonal and non-orthogonal grid system are available for the discretization. The code includes optimizing capability for different types of hardware systems
Difference method, FEM and finite volume method
Solving sparse matrix equations by iterative methods
Domain decomposition
C++, Fortran90, MPI, OpenMP, zlib, libxml2
Source code is available through ISLIM download site.
- Three dimensional heat conductance equation for a benchmark test
- The number of voxels: 8192x2048x2048
- Required memory/disk storage: 4 TB/1 TB (RICC's 8192 cores)
Overall simulation in physics, etc.
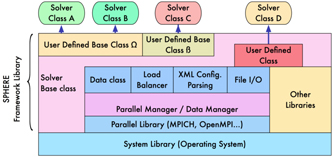
Figure 1. SPHERE framework library.
- SPHERE is middleware that helps develop a variety of application codes.
Kimito FUNATSU, Professor, Laboratory of Chemoinformatics, University of Tokyo
The VLSVL provides a nonconventional large scale virtual library avoiding the following conventional issues: (1) the investigation of synthesis requires large cost after getting high score lead compounds because of a virtual library, and (2) unstable compounds being not syntheticable are often obtained if we only depend on the atomic specie combinations and the logical manipulations of atom's bond orders for the compound creation.
Using the conformation change transform around the reaction time at the reacting sites, the library provides precursor conformations for a target conformation as a reaction scheme
Fortran
Not released for public.
- The first step gives 6.3 million virtual compounds and 12 million virtual reaction schemes out of 420 thousands of compounds
- The output from the first step are entered as input data so that 100 million compounds are obtained.
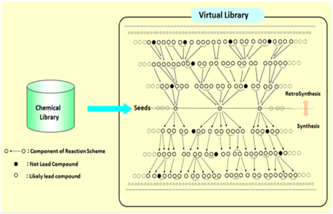
Figure 1. The structure of the virtual library.
- The VLSVL gives a large scale virtual library with synthetic routes: (1) Synthetic path for obtainable compounds, and (2) cost evaluation for each synthetic path
- The VLSVL keeps high output conformation novelty: only 0.004% duplications happened between the 6.3 million output conformations and a commercial reagent library with 15 million molecules
- Fewest unsynthetical conformations are created.